
Recent releases of wolfSSL have included new assembly code targeted at the Intel x86_64 platform. Large performance gains have been made and are being discussed over six blog posts of which this is part 2. In this blog, we will talk about the performance of ChaCha20-Poly1305.
ChaCha20-Poly1305 is a relatively new authenticated encryption algorithm. It was designed as an alternative to AES-GCM. The algorithm is simple and fast on CPUs that do not have hardware acceleration for AES and GCM.
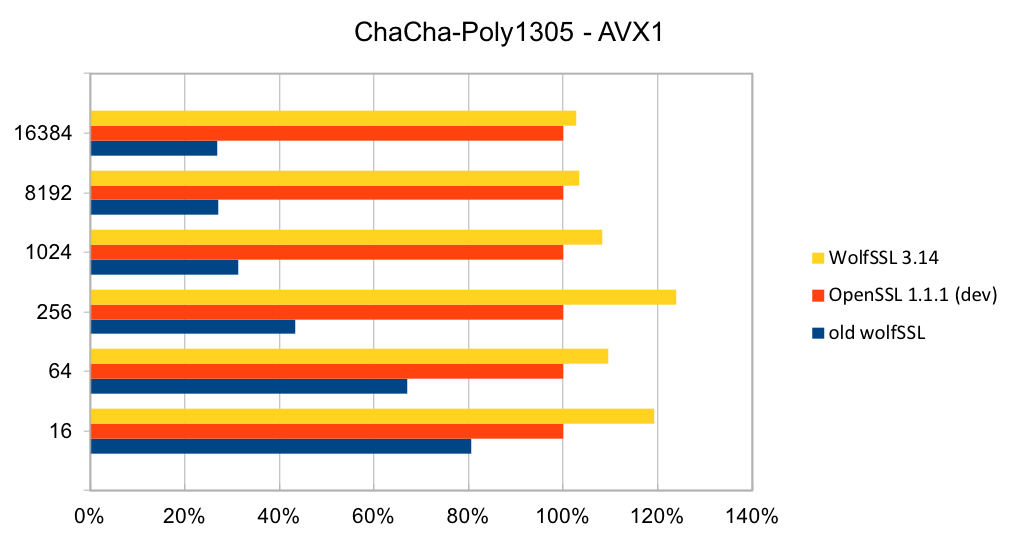
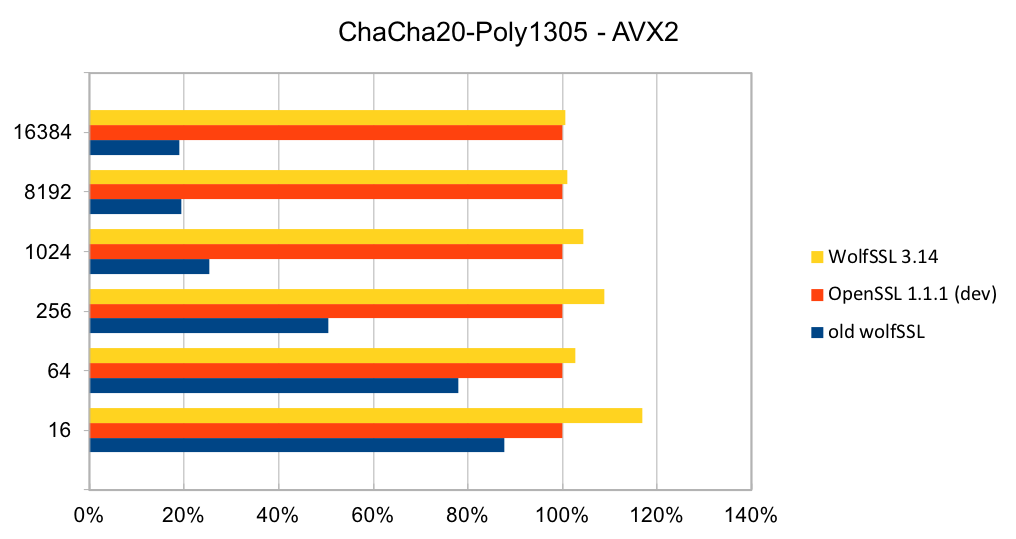
Older releases of wolfSSL did not have assembly code implementations of ChaCh20 or Poly1305. So, adding assembly code that uses AVX1 and AVX2 instructions has made a significant difference. The two charts below show the performance of wolfSSL with respect to OpenSSL on AVX1 and AVX2 chipsets. In both charts, the new assembly code is a clear improvement over the C code. Compared to OpenSSL, wolfSSL is between 2.5% and 23% faster on AVX1 and on AVX2 they are the same speed to wolfSSL being 16% faster!
If you have questions about the performance of the wolfSSL embedded TLS library, please contact us at support@wolfssl.com!
References: